Algorithm Workflow
Our multi-stage deep learning pipeline for Brain tumor classification
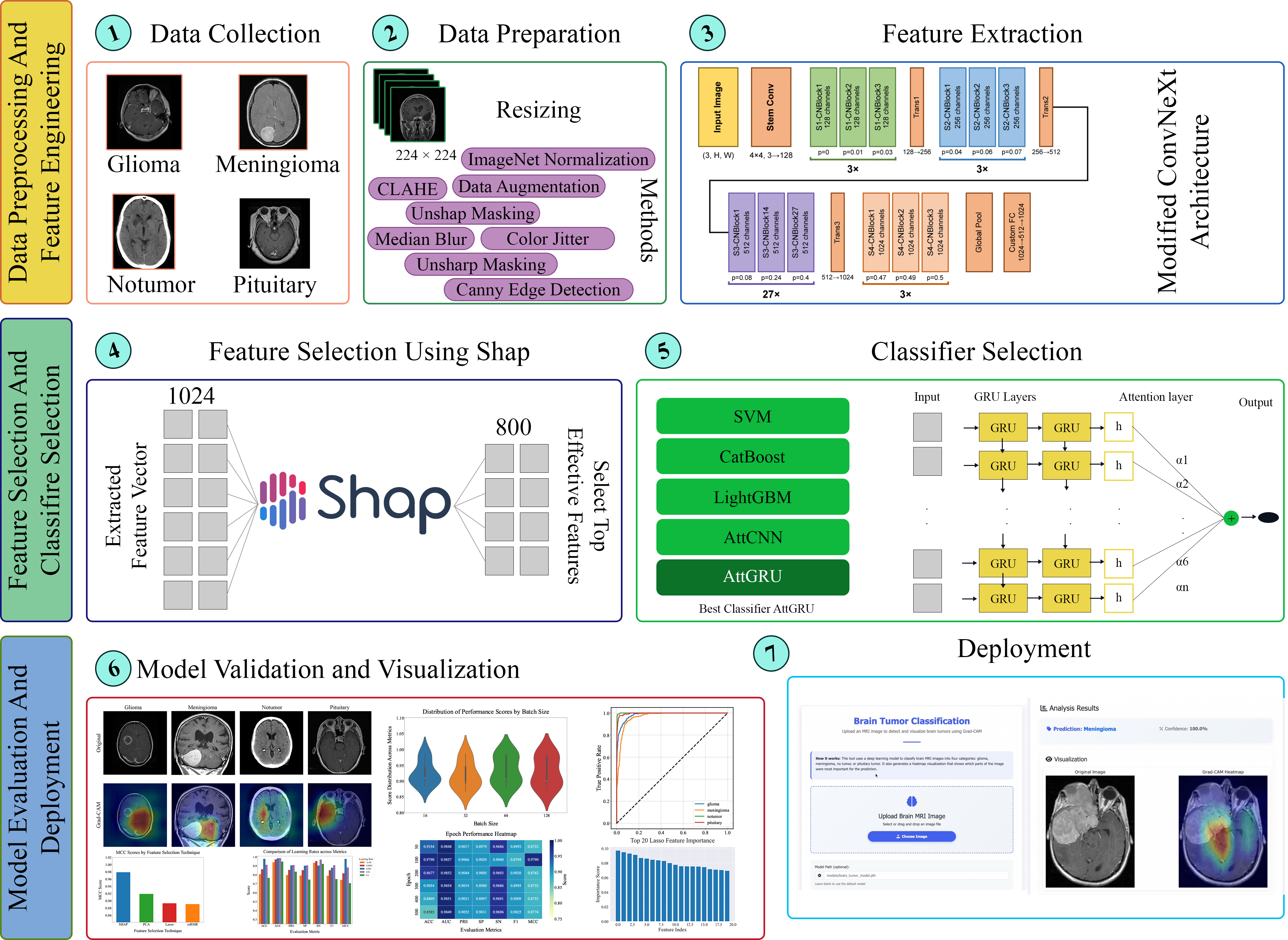
Figure 1: Overall pipeline of the proposed brain tumor classification framework, including MRI data preprocessing, ConvNeXt-based feature extraction, SHAP-based feature selection, and AttGRU classification.
Methodology & Approach
Detailed breakdown of our multi-stage deep learning approach
Stage 1: Data Preprocessing
Histogram equalization, Gaussian blur, bilateral filtering, and CLAHE for contrast enhancement and noise reduction
Data augmentation: random horizontal flips, rotations, affine transforms, gamma correction, sharpening, and color jittering
Standardized resizing from 216×250 to 224×224 with channel-wise normalization (mean: 0.485, 0.456, 0.406; std: 0.229, 0.224, 0.225)
Stage 2: Feature Extraction
Modified ConvNeXt-Base backbone pre-trained on ImageNet (IMAGENET1K_V1)
FC refinement block: 1024 → 512 (ReLU + Dropout 0.3) → 1024 dimensions
Extraction of 1024-dimensional high-level feature vectors
Stage 3: Feature Selection
SHAP (SHapley Additive exPlanations) analysis using XGBoost for feature importance scoring
Ranking features in descending order of importance
Selection of optimal top-800 features for maximum classification performance
Stage 4: Classification
Attention-based GRU (AttGRU) classifier
GRU layer captures sequential dependencies; attention module assigns importance weights
Dropout (0.1) + fully connected layer with sigmoid activation for final prediction
High-precision multiclass prediction (97.90% Accuracy, 98.57% AUC)
Key Innovations
Novel contributions and technological advances in our approach
Hybrid ConvNeXt-AttGRU architecture for capturing hierarchical and sequential feature dependencies
SHAP-guided feature optimization selecting top-800 most discriminative features
Robust performance (97.90% Acc, 98.57% AUC) surpassing SVM, CatBoost, LightGBM, and AttCNN baselines
Grad-CAM and attention-based visualizations for explainable and clinically trustworthy AI
Technical Architecture
Deep learning components and model architecture details
Feature Extraction
ConvNeXt-Base
Modified ConvNeXt backbone with depthwise separable convolutions and large kernels; original classification head replaced with identity mapping for deep feature embedding
FC Refinement Block
Custom fully connected block projecting 1024 → 512 → 1024 dimensions with ReLU activation and dropout (0.3) for overfitting mitigation
Feature Selection
SHAP Analysis
Game-theoretic approach using XGBoost to compute Shapley values and rank feature contributions
Optimal Subset
Reduction to top-800 most critical features for maximum discrimination and classification performance
Classification
AttGRU Classifier
Attention-based GRU model with update and reset gates; attention mechanism dynamically weights GRU outputs to emphasize discriminative features
Optimization
Training with AdamW optimizer, CrossEntropyLoss, learning rate 0.001, batch size 64, over 100 epochs
Model Performance Metrics
Experience Our Algorithm in Action
Test our multi-stage deep learning approach with your own medical images or explore our sample dataset